为什么需要重读word2vec
Word2vec原论文:
- Tomas Mikolov, Kai Chen, Greg Corrado, and Jeffrey Dean. Efficient estimation of word representations in vector space. CoRR, abs/1301.3781,2013.
- Tomas Mikolov, Ilya Sutskever, Kai Chen, Gregory S. Corrado, and Jeffrey Dean. Distributed representations of words and phrases and their compositionality. NIPS 2013.
其中1主要是描述CBOW和Skip-Gram相关方法,2描述了Negative Sampling以及训练word2vec的方法。为什么想要重读word2vec:
- 推荐系统中,可以把item或user类比与word2vec中的word,很多i2i和u2i的方法都是借鉴的word2vec,以及召回中常用的NCE Loss和Sampled Softmax Loss都和word2vec相关;熟悉word2vec对了解召回,对如何像Aribnb KDD18和阿里EGES一样将word2vec改进应用到具体业务中,会非常有帮助;
- 召回热门样本的处理,也可以借鉴word2vec中热门词的处理思路;
- GPT的输入词是字符串,怎么表征输入到NN?当然,现在大家都很熟悉了embedding lookup table,embedding lookup table的其实最早差不多就是来自word2vec(更早影响没那么大暂且不提);
- word2vec是老祖级别的语言模型,那么最新的GPT和它主要区别在哪里?
- 初次看GPT代码时,发现GPT的输出是softmax,word2vec其实loss也是softmax loss。但为什么在word2vec里面的softmax就需要Negative sampling,而GPT里却不需要?
基于上下文的Embedding学习:CBOW和Skip-Gram
在word2vec之前,主要还是根据词频信息来表征词的特征。举个例子,每个词在不同的文章中出现的次数作为词的表征,然后通过PCA和Topic Models等无监督学习的方法学习词的Embedding,总体效果不够好。
doc1 doc2 doc3
这 5 2 1
北京 1 0 0
天安门 2 1 0
游客 1 2 2
word2vec核心思想是通过训练神经网络来预测上下文,利用上下文的监督信号学习word的Embedding,这样Embedding中就隐含了上下文信息。word2bec训练embedding的思想对推荐系统、以及Bert/GPT等都影响深远。Word2vec一般有两种训练方法:
- CBOW: Continuous Bag-of-Words,BoW即用其他词表示当前词
- Skip-Gram Model
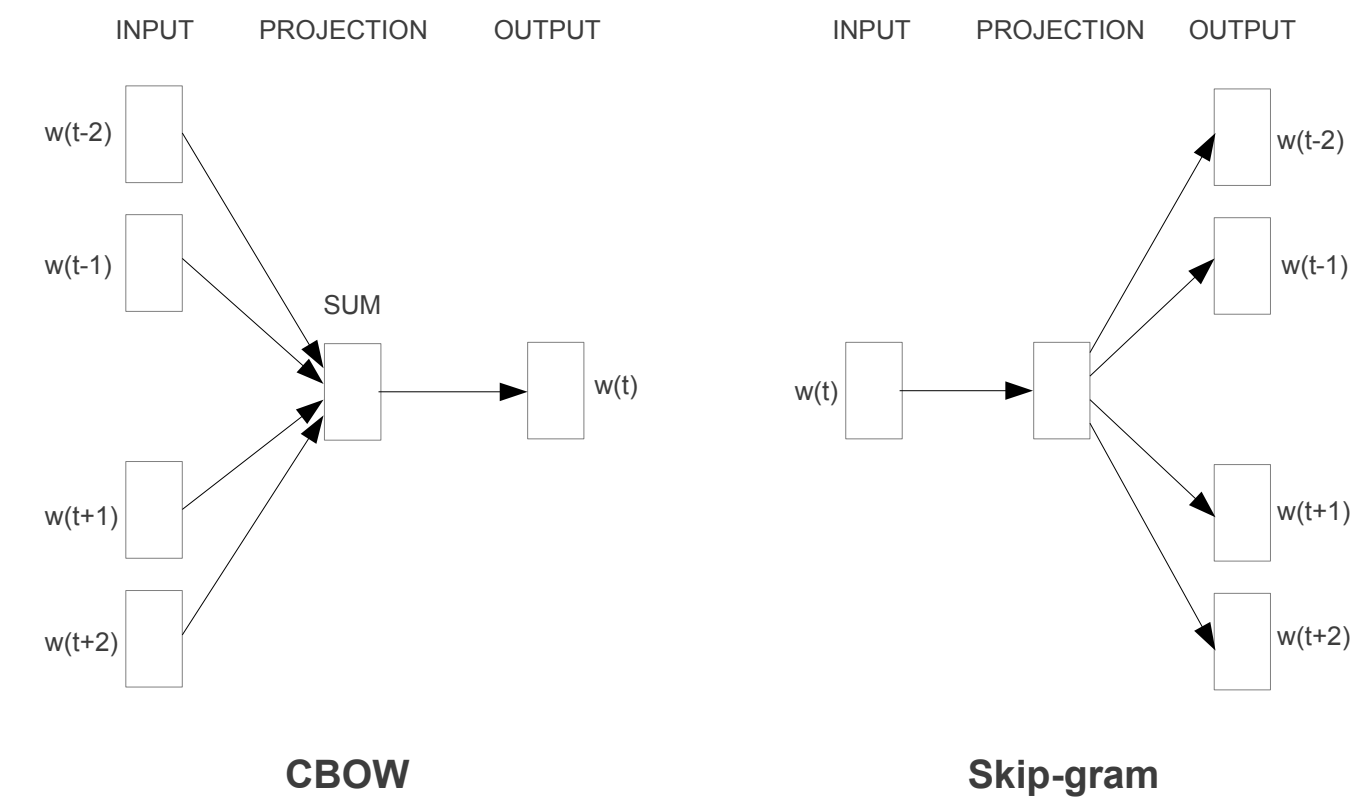
CBOW是通过上下文(Context)预测当前word(BERT中的完形填空跟这个类似),假设词与词之间相互独立,则对应的极大似然学习目标为:
$$ E=-\log p(w_t|w_{t-1},w_{t-2},..,w_{t-c},w_{t+1},w_{t+2},...,w_{t+c}) \\ = -\log \frac{e^{h \cdot v'_o} }{\sum_{j \in V} e^{h \cdot v'_j }} \\ = - h \cdot v'_o + \log {\sum_{j \in V} e^{h \cdot v'_j}} $$其中,
- c是context窗口大小,在一个context内就是正样本,是个人工超参数,或根据一定规则动态调整;
- Loss函数使用的Softmax多分类,类目数即为词典大小V(语言模型里面,V大概几万-十万),即预估中心词是字典中的哪一个;
- h是CBOW的隐藏层输出,所有输入$w_{t-1},w_{t-2}…,w_{t+1},w_{t+2}$通过lookup table查到embedding查询得到 $v_{t-1},v_{t-2}…,v_{t+1},v_{t+2}$之后,再进行sum pooling的结果;即$h=1/C*(v_{t-1},v_{t-2},…,v_{t+1},v_{t+2},…)$,C为上下文长度;输入表达矩阵(lookup table)存储的就是word embedding的结果;
- v’是输出矩阵表达,注意在word2vec里面,和输入表达矩阵(即lookup table)不共享参数(GPT中的Head和输入Lookup Table是共享参数);
- 模型假设 = h * v’:输入表征和预估词表征的点乘运算,可以理解为是输入context的embedding(即sum pooing结果)和输出v’的内积相似度,最终loss算的是这个相似度的softmax loss;
Skip-Gram与CBOW相反,它是则根据当前word来预估可能的上下文概率,对应的极大似然估计目标为:
$$ E=-\log p(w_{t-1},w_{t-2},...,w_{t-c},w_{t+1},w_{t+2},...,w_{t+c}|w_t) \\ =-\log p(w_{t-1}|w_t,..,w_{t-c}|w_t,...,w_{t+1}|w_t,...,w_{t+c}|w_t) \\ =-\log \prod_{o \in C} p(w_o|w_t) \\ =-\sum_{o \in C} \log \frac{e^{v_i \cdot v'_o} }{\sum_{j \in V} e^{v_i \cdot v'_j }} \\ =-\sum_{o \in C} {v_i \cdot v'_o} + C \log \sum_{j \in V} e^{v_i \cdot v'_j } $$其中,
- Loss函数也是使用的Softmax多分类,类目数即为词典大小V;相比CBOW,这里最外层多了对Context的求和,C即为Context;
- $v_i$是输入word通过lookup table查到的embedding,没有也无需sum pooling操作,因为Skip-Gram输入只有一个词;
- 同样的,v’是输出矩阵表达,注意在word2vec里面,和输表达入矩阵(即lookup table)不一样;
- v_i * v’ 点乘运算,可以理解为是当前词的embedding和Context里每个词的embedding计算相似度(注意这里输出词的embedding和输入词不是同一个词表);
- 正样本为上下文内的样本,负样本为大词典V中的其他样本,loss函数为softmax。
到目前为止,已经有了CBOW和Skip-Gram的原始优化目标,实际上不管是CBOW还是Skip-Gram都是建模成词典大小的softmax多分类问题。但是有个很棘手的问题——计算复杂度。假设词表大小是V,隐藏层维度是H,则每次loss计算,softmax的分母就需要$O(V*H^2)$次的乘法,这是不可接受的。
Negative Sampling
为了有效的解决计算复杂度的问题,工程实现上有 Hierarchical Softmax 和 Negative Sampling的方法。Hierarchical Softmax在工业界用得不多,Negative Sampling相对更容易实现,所以这里只讨论Negative Sampling。Negative Sampling顾名思义,就是为每个正样本采集多个负样本,然后用采样结果训练。采样后训练方法主要有Sampled Softmax Loss和NEG Loss。
原始Softmax一种比较直观的近似是 Sampled Softmax Loss:,采集多少个负样本就认为是多少类的多分类问题。比如采集负样本集合$S_{neg}$,则加上要预估词共N=$len(S_{neg})+1$类,然后用softmax学习从N类中预估正样本的概率,
$$ \text{SampledSoftmaxLoss}= \log \frac {e^{v_i \cdot v'_o}}{e^{v_i \cdot v'_o} + \sum_{j \in S_{neg}} e^{v_i \cdot v'_j}} $$另一种Negative Sampling训练方法是word2vec原文提出的 NEG Loss:采集到的负样本都是噪声,学习目标是利用binary cross entropy从噪声中分类得到正样本,
$$ \text{NEGLoss}=-log (\frac {1}{1+e^{-v_i \cdot v'_o}}) - \sum_{j \in S_{neg}} log (1 - \frac {1}{1+e^{-v_i \cdot v'_j}}) \\ =-log\ \sigma(v_i \cdot v'_o) - \sum_{j \in S_{neg}} log\ \sigma(-v_i \cdot v'_j) $$NEG更具体的一个例子:构造样本,中心词w与上下文c同属一个窗口,则<w,c>样本的label为1;随机采样一些上下文c’,则 <w,c’>的样本label为0。建模w和context的联合概率$p(w,c)$——二分类就是sigmoid函数,不同于Skip-Gram和CBOW里面的条件概率,对应Loss为:
$$ NEGLoss = -\log (\prod_{(w,c) \in D_p} p(D=1|w,c) + \prod_{(w,c') \in D_n} p(D=0|w,c') ] ) \\ = -\sum_{(w,c) \in D_p} \log \frac{1}{1+e^{-v_c \cdot v_w}} - \sum_{(w,c') \in D_n} \log (1 - \frac{1}{1+e^{-v_c' \cdot v_w}}) \\ = -\sum_{(w,c) \in D_p} \log \sigma(v_c \cdot v_w) -\sum_{(w,c') \in D_n} \log (1-\sigma(v_c' \cdot v_w)) $$其中,Dp是正样本集合,Dn是采样的负样本集合。
NCE(Noise Contrastive Estimation) 关于NEG Loss,实际是对比学习中常用的NCE(Noise Contrastive Estimation)的简化版本,有文献证明NCE Loss可以无限近似原始的极大似然的softmax loss。NCE是利用对比学习,从噪声中学习正样本的方法。假设有一个样本u,预估为正样本的概率为$p_{\theta}(u)$, 预估为来自于噪声的概率是$q(u)$,NCE学习目标是正样本相比噪声样本的logit,即
$$g = log\frac{p_{\theta}(u)}{q(u)} $$因为g是logit值,计算sigmoid后代入cross entroy loss即得到NCE Loss,
$$ L_{NCE}(\theta) = -\frac{1}{|S|}\sum_{u \in S} [log(\sigma(g))+log(1-\sigma(g))] $$NCE怎么简化得到NEG呢?实际就是logit取值的时候丢弃掉q,把g拆开q实际就是一个偏置,对最终学习概率的准度/分布有影响,但对于word2vec的目标是“学习有效的embedding”影响不大。
高频词降采样
为了很好的完成对word embedding的训练,还有一个问题:对于’a’, ’the’, ‘in’这种词,出现频率很高,但信息含量又很低,频繁的送入word2vec模型反而容易把模型带偏。为了处理这种imbalance的高频词,在训练时,word2vec采用下面的概率对word进行随机丢弃:
$$ P(w_i)=1-\sqrt{\frac{t}{f(w_i)}} $$其中
- f(w_i)就是词w_i出现的频率。100个词里面出现10词,则=1/10,代表热度;
- t是一个人工选定的阈值(原文$10^{-5}$);
Word2vec的后续演进
GloVe (Global Vector Model)
Glove想结合文章开头的词频和Skip-Gram方法。
LLM (Large Laguage Model)
BERT和GPT延续了word2vec表征一切的思路,用大数据pre-training就能得到NLP的非常好的表征。然后,只要针对具体业务场景的少量数据做fine-tuning就可以达到很不错的效果。BERT和GPT相比word2vec的主要优势在于,word2vec只考虑了单个词的表征,没有考虑词在不同上下文下的差异,比如 apple 在I have an apple laptop和I want eat apple里面含义是完全不同的,所以用于表征apple的embedding也应该是不同的。
这里试着回答开头困惑的问题:
GPT的输出是softmax,word2vec其实loss也是softmax loss。但为什么在word2vec里面的softmax就需要Negative sampling,而GPT里却不需要?
答:因为word2vec里面softmax的分母,包含了输入表征和输出表征向量的inner product,且每次迭代都要计算V次,这才是计算量大的根源,复杂度$O(V*H^2)$;而GPT最后一层是lm_head(nn.Linear层),假设lm_head前的隐藏层输出为H,词典大小为V,复杂度仅为O(VH),自然可以直接计算softmax loss。
推荐算法中的应用
Item2vec
把item类比成word2vec中的word,就有了item2vec,利用item的vector进行i2i协同过滤。且item2vec中使用了和word2vec一样的高频词降采样方法对热门item打压。
Real-time Personalization using Embeddings for Search Ranking at Airbnb
Aribnb分别采用:
- 用户click session的数据生成listing的embedding,捕捉短期的实时个性化;
- 用户booking session的数据生成user-type和listing-type的embedding,捕捉中长期用户兴趣;
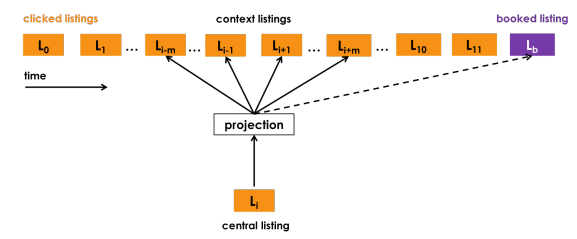
Listing embedding采用word2vec中的Skip-Gram模式(如下图),用户点击序列类比于word2vec的上下文,但是相比word2vec又做一些应用场景的适配:
- 除了考虑上下文,如果有booking,在推荐中被认为是一个强信号,将booking也加到context中;因此其优化目标除了word2vec中的正负样本,还增加了booking listing的正样本(下面优化目的第3项);
- 酒店预定一般具有地理特性,即用户一般一个session都在浏览同一地区的酒店,如果只采用word2vec中的随机负采样,引入的都是easy样本(直接通过地区信号就能分辨出负样本),因此还需要引入一些hard samples,从central listing的相同地区采样部分hard样本,构成下面优化目标中的第4项;
| Listing Embedding | optimization target |
|---|---|
 | 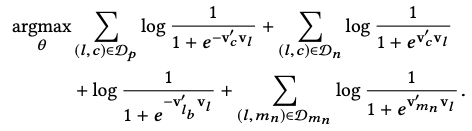 |
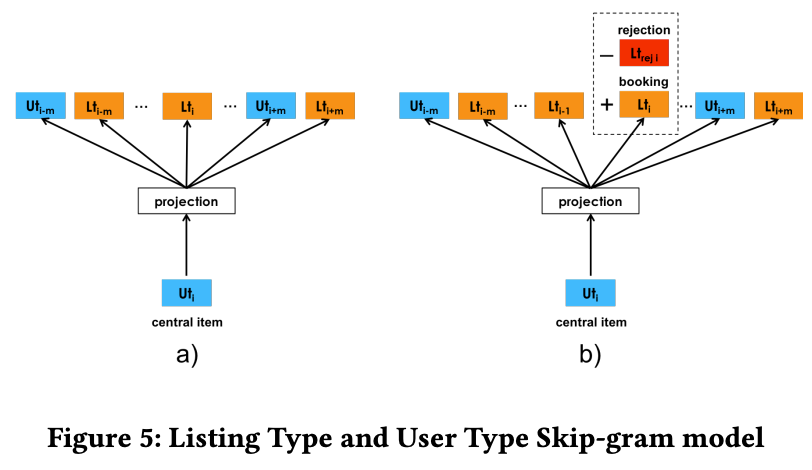
User-type和Listing-type Embedding也是Skip-Gram model,然后针对应用场景做特定的优化。
EGES
Billion-scale Commodity Embedding for E-commerce Recommendation in Alibaba
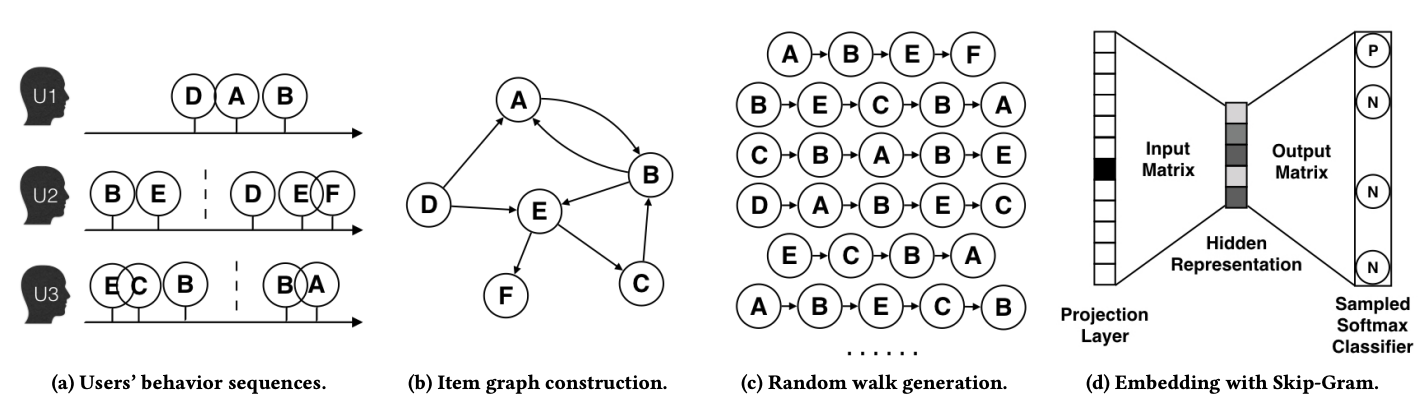
将word2vec中文本序列的表达扩展到graph的表达,将多个用户的行为序列画在graph上,在graph上随机游走生成新的item序列(类比text context window),根据生成的item序列用Skip-Gram学习item embedding表达。
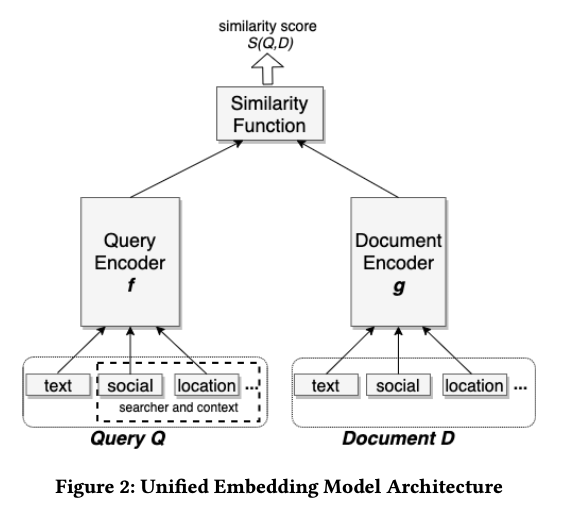
双塔召回
各大厂里面有很多将双塔用于推荐召回的例子,其采用的loss和负采样方法都一定程度借鉴的word2vec。比如:
- Microsoft: DSSM 2013:DSSM用于文档检索
- Google Youtube: Sampling-bias-corrected neural modeling for large corpus item recommendations, 2019:Youtube双塔召回
- Google Play: Mixed Negative Sampling for Learning Two-tower Neural Networks in Recommendations, 2020:google play双塔召回
- Facebook: Embedding-based Retrieval in Facebook Search, 2020:详细介绍了Facebook基于Embedding召回的工程实践,有很多工程细节关于如何进行负采样,采用的triplet loss也是对比学习的一种(triplet loss原则上应该也能用于word embedding的学习?)
关于DSSM用于召回本身有很多工程细节,需要单独一篇文章去讲解。双塔最基本的结构基本如下:Query和Document的Embedding可以对应word2vec的输入表达和输出表达矩阵,只是word2vec的输入表达和输出表达都是word,而双塔模型中可能是i2i,也可能是u2i。
双塔模型的negative sampling和loss函数与word2vec不能说很相似,有的完全一样:
- Microsoft的DSSM:采用negative sampled softmax loss,$ P(D|Q) = \frac{exp(\gamma R(Q,D))}{\sum_{D’ \in \bold{D}} exp(\gamma R(Q,D’))} $,就是sampled softmax loss,增加了温度超参数$\gamma$;
- Youtube是Sampled softmax loss的变种。
参考
- Xin Rong. word2vec Parameter Learning Explained. 2016.
- Goldberg, Y. and Levy, O. (2014). word2vec explained: deriving mikolov et al.’s negativesampling word-embedding method. arXiv:1402.3722 [cs, stat]. arXiv: 1402.3722.
- Mikolov, T., Chen, K., Corrado, G., and Dean, J. (2013a). Efficient estimation of word representations in vector space. arXiv preprint arXiv:1301.3781.
- Mikolov, T., Sutskever, I., Chen, K., Corrado, G. S., and Dean, J. (2013b). Distributed representations of words and phrases and their compositionality. In Advances in Neural Information Processing Systems, pages 3111–3119.
- Grbovic, Mihajlo, and Haibin Cheng. “Real-time personalization using embeddings for search ranking at airbnb.” Proceedings of the 24th ACM SIGKDD international conference on knowledge discovery & data mining . 2018.
- nanoGPT. https://github.com/karpathy/nanoGPT/blob/325be85d9be8c81b436728a420e85796c57dba7e/model.py#L138C60-L138C107
- https://lilianweng.github.io/posts/2017-10-15-word-embedding/